Assumptions can ruin your k-means clusters
Clustering is one of the most powerful and widely used of the machine learning techniques. It’s very seductive. Throw some data into the algorithm and let it discover hitherto unknown relationships and patterns.
k-means is the most popular of all the cluster algorithms. It’s easy to understand—and therefore implement—so it’s available in almost all analysis suites. It’s also fast. What’s not to like?
When people are first exposed to machine learning k-means clustering is one technique that creates immediate excitement. They "get it" pretty quickly and wonder what it might show when they get back to the office and run it on their own data.
Let’s apply k-means to the following two-dimensional dataset.

If we ask the algorithm to identify four clusters we get
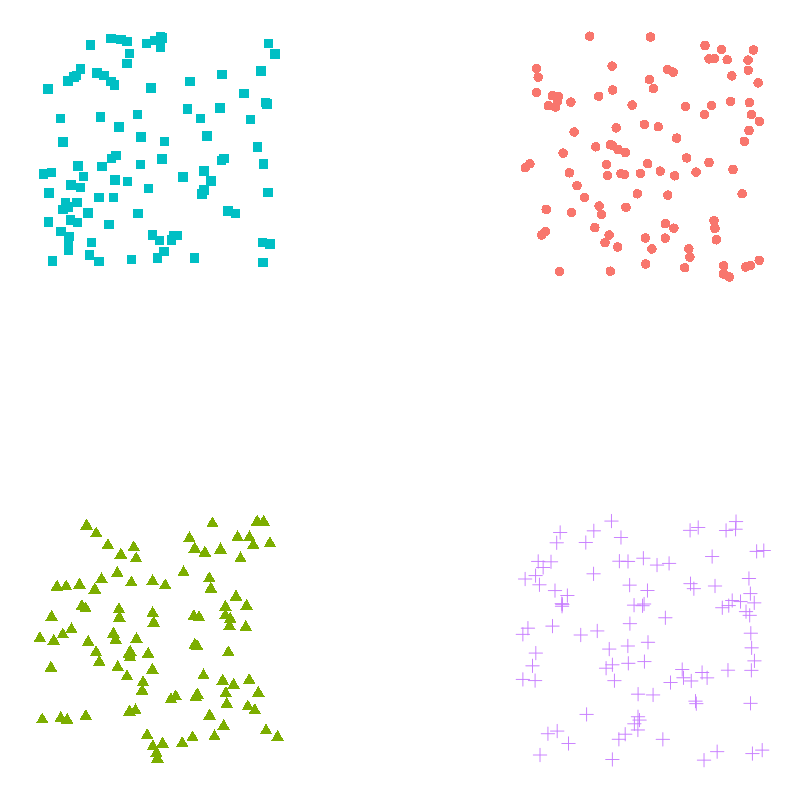
No surprise there. That’s good. The clusters are clear as day. If the k-means algorithm suggested anything else we’d be unimpressed.
However, the effectiveness of k-means rests on several (usually implicit) assumptions about your dataset. These assumptions match our intuition about what a cluster is—which makes them dangerous. There are traps for the unwary.
Two assumptions made by k-means are
- Clusters are spatially grouped—or "spherical"
- Clusters are of a similar size
Imagine manually identifying clusters on a scatterplot. You’d take your pen and circle distinct groups. That’s similar to how k-means operates. It identifies spherical clusters.
The assumption about similar-sized clusters is less intuitive. We’d have no problem manually identifying small, isolated, distinct clusters in a dataset. However, the optimization approach used by k-means—effectively minimizing the distance between all the points in each cluster—can lead it astray.
k-means lacks any judgement. When its simple rules fail it has no ability to reflect on the trade-offs.
Let’s see examples of k-means breaking spectacularly when we deviate from these assumptions.
Non-spherical clusters
Examine the following scatter plot.

Two clusters, right? Easy. One small ring surrounded by a larger ring. Clear separation between them.
However, only ring is a spherical cluster—the inner one. If you drew a circle around the outer cluster/ring it would have to encompass the inner one. How will k-means handle this violation of one if its core assumptions?
Let’s see.
We know there are two clusters so we’ll help by telling it that’s how many we’d like identified. Here’s what it finds.
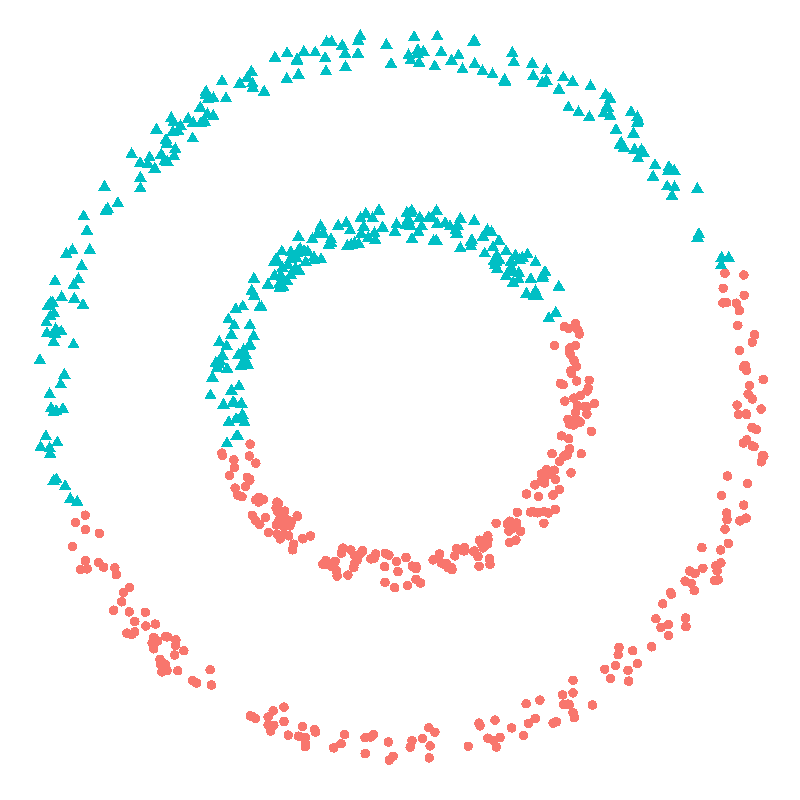
Oh dear.
However, we can help the algorithm out. If we understand our domain—and we do in this simple case—we can transform the data into a form that adheres to the aforementioned assumptions.
As we are dealing with circles, if we transform our Cartesian (x vs y) coordinates to polar (arc vs radius) coordinates, we end up with two distinct rectangular clusters. They have the same arc range, but are partitioned by their radii.

Running k-means on the transformed dataset gives us the following two clusters—displayed using the original Cartesian coordinates.

Perfect. The job of the data scientist is often to set the ball up so that the techniques can hit the back of the net.
Different-sized clusters
Consider the following dataset.

Again, there are two obvious clusters. One small, tightly grouped cluster and another, larger, more dispersed cluster. These are spatially grouped, so no problem on that front.
Let’s use k-means to identify our two clusters.

Hmmm. Not good. What happened here?
k-means tries to produce "tight" clusters. In attempting to minimize the intra-cluster distances between the points in the large cluster it’s "overdone" things and produced two clusters that have similar intra-cluster distances. However, it’s clear that this is a terrible solution for our dataset.
Conclusions
Sadly, we can’t treat machine learning as a black box into which we shovel coal and expect diamonds at the other end. We need to understand the implicit and explicit assumptions in the tools we use and consider how they will impact our results.
k-means clustering is powerful. But it’s blind. And, occasionally, it can make spectacular mistakes. The same is true for all other machine learning methods. Use with caution.
There’s no substitute for being intimately familiar with your data. That’s why the best data science is performed by those who have, or have access to, domain expertise.
